Excel-regneark inneholder ofte celleutkast for å forenkle og / eller standardisere dataregistrering. Disse rullegardinene er opprettet ved hjelp av datavalideringsfunksjonen for å angi en liste over tillatte oppføringer.
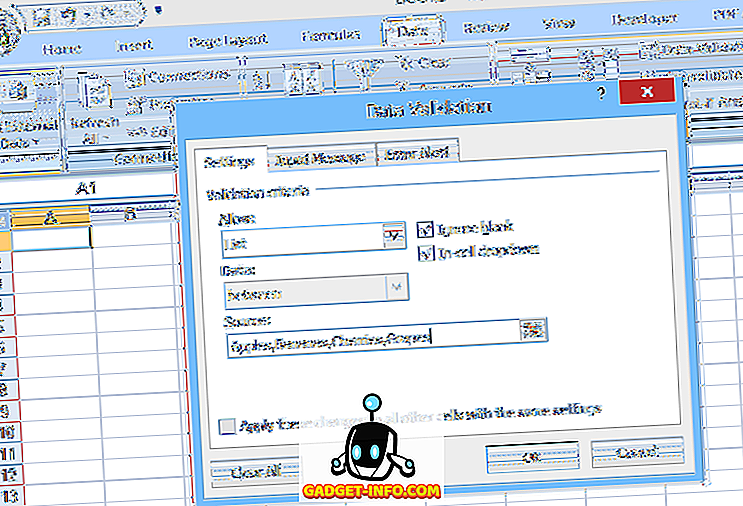
For å sette opp en enkel rullegardinliste, velg cellen der data skal skrives inn, og klikk deretter Datavalidering (på Datafelt ), velg Datavalidering, velg Liste (under Tillat :), og skriv deretter inn listeelementene (separert med kommaer ) i Kilde : -feltet (se figur 1).
I denne typen grunnleggende rullegardin er listen over tillatte oppføringer angitt innenfor datavalideringen selv; Derfor må brukeren åpne og redigere datavalideringen for å gjøre endringer i listen. Dette kan imidlertid være vanskelig, for uerfarne brukere, eller i tilfeller hvor listen over valg er lang.
Et annet alternativ er å plassere listen i et navngitt område i regnearket, og angi deretter rekkevidde-navnet (prefaced med et likestilt) i Kilde : -feltet for datavalidering (som vist på figur 2).
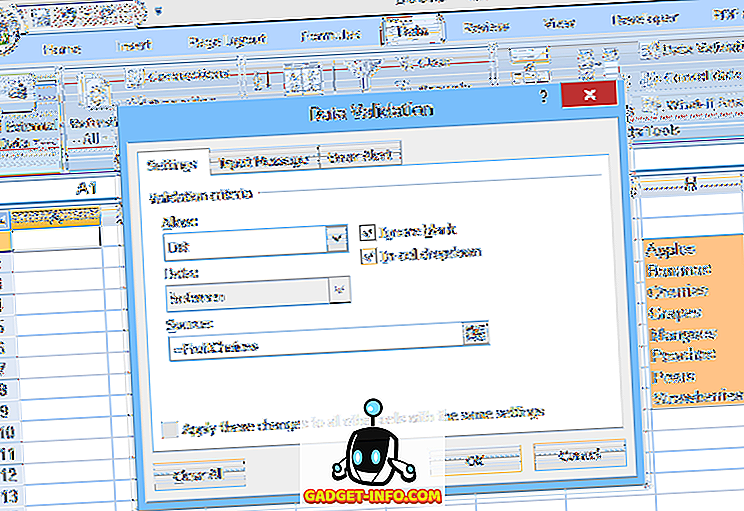
Denne andre metoden gjør det enklere å redigere valgene i listen, men å legge til eller fjerne elementer kan være problematisk. Siden det nevnte området (FruitChoices, i vårt eksempel) refererer til et fast utvalg av celler ($ H $ 3: $ H $ 10 som vist), hvis flere valg legges til cellene H11 eller under, vil de ikke dukke opp i rullegardinmenyen (siden disse cellene ikke er en del av FruitChoices-serien).
På samme måte hvis for eksempel pærene og jordbær-oppføringene blir slettet, vil de ikke lenger vises i rullegardinmenyen, men i stedet vil rullegardinmenyen inneholde to "tomme" valg, ettersom rullegardinmenyen fortsatt refererer til hele FruitChoices-serien, inkludert de tomme cellene H9 og H10.
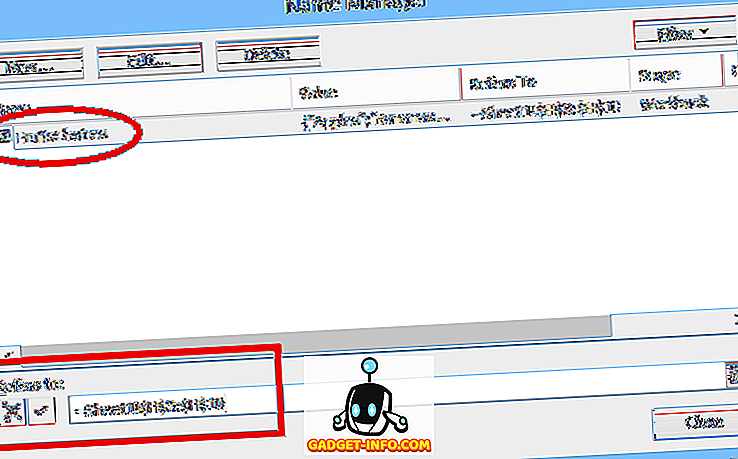
Av disse årsakene, når du bruker et normalt navngitt område som listekilden for en rullegardin, må navnetavsnittet i seg selv redigeres for å inkludere flere eller færre celler hvis oppføringer blir lagt til eller slettet fra listen.
En løsning på dette problemet er å bruke et dynamisk rekkevidde navn som kilden for dropdown valgene. Et dynamisk områdenavn er en som automatisk ekspanderer (eller kontrakter) for å nøyaktig matche størrelsen på en blokk med data ettersom oppføringer er lagt til eller fjernet. For å gjøre dette bruker du en formel, i stedet for et fast rekkevidde av celleadresser, for å definere det angitte området.
Slik oppretter du et dynamisk område i Excel
Et normalt (statisk) områdenavn refererer til et spesifisert utvalg av celler ($ H $ 3: $ H $ 10 i vårt eksempel, se nedenfor):
Men et dynamisk område er definert ved hjelp av en formel (se nedenfor, hentet fra et eget regneark som bruker dynamiske rekkevidde navn):
Før vi begynner, må du laste ned vår Excel-eksempelfil (sorteringsmakroer er deaktivert).
La oss undersøke denne formelen i detalj. Valgene for frukt er i en blokk med celler rett under en overskrift ( FRUITS ). Den overskriften er også tildelt et navn: FruitsHeading :
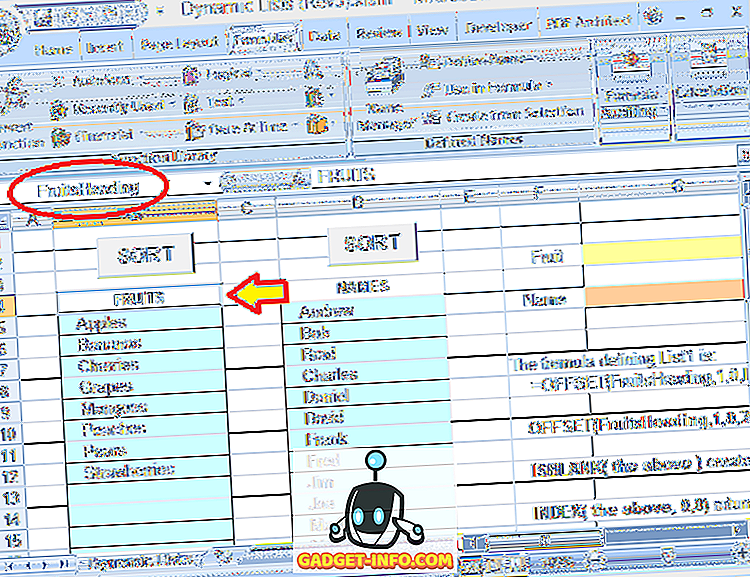
Hele formelen som brukes til å definere det dynamiske området for fruktens valg er:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEKS (ISBLANK (OFFSET (FruitsHeading, 1, 0, 20, 1)), 0, 0), 0) -1, 20), 1)
FruitsHeading refererer til overskriften som er en rad over den første oppføringen i listen. Tallet 20 (brukt to ganger i formelen) er maksimal størrelse (antall rader) for listen (dette kan justeres etter ønske).
Merk at i dette eksemplet er det bare 8 oppføringer i listen, men det finnes også tomme celler under disse hvor flere oppføringer kan legges til. Tallet 20 refererer til hele blokken der oppføringer kan gjøres, ikke til det faktiske antall oppføringer.
La oss nå bryte ned formelen i stykker (fargekoding hvert stykke), for å forstå hvordan det fungerer:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ISBLANK ( OFFSET (FruitsHeading, 1, 0, 20, 1) ), 0, 0), 0) -1, 20), 1)
Det "innerste" stykket er OFFSET (FruitsHeading, 1, 0, 20, 1) . Dette refererer til blokkene med 20 celler (under FruitsHeading-cellen) der valgene kan skrives inn. Denne OFFSET-funksjonen sier i utgangspunktet: Start på FruitsHeading- cellen, gå ned 1 rad og over 0 kolonner, velg deretter et område som er 20 rader langt og 1 kolonne bredt. Så det gir oss den 20-rads blokken der fruktens valg er lagt inn.
Neste del av formelen er ISBLANK- funksjonen:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX ( ISBLANK (ovenfor), 0, 0), 0) -1, 20), 1)
Her er OFFSET-funksjonen (forklart ovenfor) erstattet med "ovenfor" (for å gjøre det enklere å lese). Men ISBLANK-funksjonen opererer på 20-raders rekke celler som OFFSET-funksjonen definerer.
ISBLANK lager deretter et sett med 20 TRUE og FALSE-verdier, som indikerer om hver enkelt av de enkelte cellene i 20-rad-serien referert til av OFFSET-funksjonen er tom (tom) eller ikke. I dette eksemplet vil de første 8 verdiene i settet være FALS siden de første 8 cellene ikke er tomme og de siste 12 verdiene vil være SANT.
Neste del av formelen er INDEX-funksjonen:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ovenfor, 0, 0), 0) -1, 20), 1)
Igjen, "ovenfor" refererer til ISBLANK og OFFSET-funksjonene beskrevet ovenfor. INDEX-funksjonen returnerer en matrise som inneholder de 20 TRUE / FALSE-verdiene som er opprettet av ISBLANK-funksjonen.
INDEX brukes vanligvis til å velge en bestemt verdi (eller verdiområde) ut av en blokk med data, ved å spesifisere en bestemt rad og kolonne (innenfor den aktuelle blokk). Men å sette rad og kolonneinnganger til null (som gjøres her), forårsaker INDEX å returnere en matrise som inneholder hele databasen.
Neste del av formelen er MATCH-funksjonen:
= OFFSET (FruitsHeading, 1, 0, IFERROR ( MATCH (TRUE, ovenfor, 0) -1, 20), 1)
MATCH- funksjonen returnerer posisjonen til den første TRUE-verdien, innenfor arrayet som returneres av INDEX-funksjonen. Siden de første 8 oppføringene i listen ikke er tomme, vil de første 8 verdiene i gruppen være FALSK, og den niende verdien vil være SANN (siden den 9. rad i intervallet er tom).
Så MATCH-funksjonen returnerer verdien av 9 . I dette tilfellet vil vi imidlertid virkelig vite hvor mange oppføringer som er i listen, så formelen trekker 1 fra MATCH-verdien (som gir posisjonen til den siste oppføringen). Så til slutt returnerer MATCH (TRUE, ovenstående, 0) -1 verdien av 8 .
Neste del av formelen er IFERROR-funksjonen:
= OFFSET (FruitsHeading, 1, 0, IFERROR (ovenfor, 20), 1)
IFERROR-funksjonen returnerer en alternativ verdi, hvis den angitte første verdien resulterer i en feil. Denne funksjonen er inkludert siden, hvis hele cellen av celler (alle 20 rader) er fylt med oppføringer, vil MATCH-funksjonen returnere en feil.
Dette skyldes at vi forteller MATCH-funksjonen for å se etter den første TRUE-verdien (i en rekke verdier fra ISBLANK-funksjonen), men hvis ingen av cellene er tomme, blir hele fargene fylt med falske verdier. Hvis MATCH ikke finner målverdien (TRUE) i array, søker den, og returnerer en feil.
Så, hvis hele listen er full (og derfor returnerer MATCH en feil), returnerer IFERROR-funksjonen i stedet verdien av 20 (vet at det må være 20 oppføringer i listen).
Endelig returnerer OFFSET (FruitsHeading, 1, 0, ovenfor, 1) området vi faktisk ser etter: Start på FruitsHeading-cellen, gå ned 1 rad og over 0 kolonner, velg deretter et område som imidlertid er mange rader lenge som Det er oppføringer i listen (og 1 kolonne bred). Så hele formelen sammen returnerer rekkevidden som bare inneholder de faktiske oppføringene (ned til den første tomme cellen).
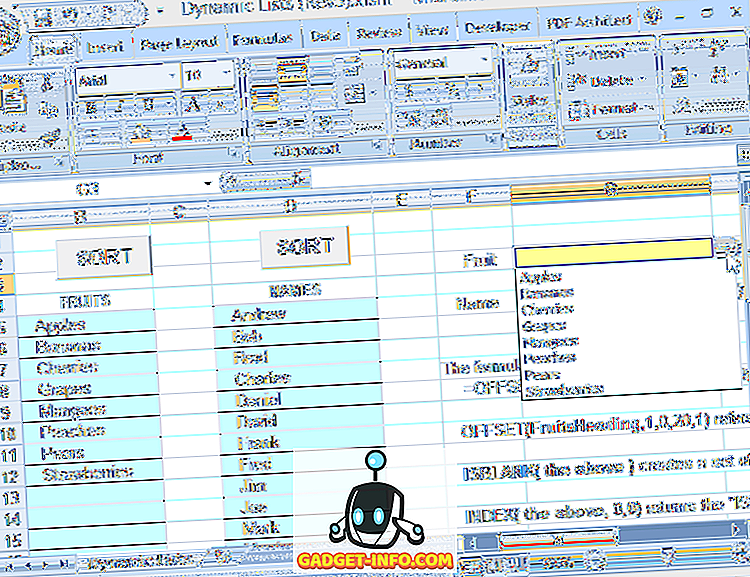
Ved å bruke denne formelen til å definere rekkevidden som er kilden til rullegardinmenyen, kan du fritt redigere listen (legge til eller fjerne oppføringer, så lenge de gjenværende oppføringene begynner på den øverste cellen og er sammenhengende) og rullegardinen vil alltid gjenspeile gjeldende liste (se figur 6).
Eksempelfilen (Dynamic Lists) som er brukt her er inkludert og kan lastes ned fra denne nettsiden. Makroene virker imidlertid ikke, fordi WordPress ikke liker Excel-bøker med makroer i dem.
Som et alternativ til å spesifisere antall rader i listeblokken, kan listeblokken tildeles sitt eget områdenavn, som deretter kan brukes i en modifisert formel. I eksempelfilen bruker en annen liste (Navn) denne metoden. Her er hele listeblokken (under overskriften "NAMES", 40 rader i eksempelfilen) tilordnet navnet på navnet på NameBlock . Den alternative formelen for å definere navnelisten er da:
= OFFSET (NamesHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ISBLANK ( NamesBlock ), 0, 0), 0) -1, ROWS (NamesBlock) ), 1)
hvor NamesBlock erstatter OFFSET (FruitsHeading, 1, 0, 20, 1) og ROWS (NamesBlock) erstatter 20 (antall rader) i den tidligere formelen.
Så, for nedlastingslister som lett kan redigeres (inkludert av andre brukere som kan være uerfarne), kan du prøve å bruke dynamiske rekkevidde navn! Og merk at selv om denne artikkelen har blitt fokusert på dropdownlister, kan dynamiske rekkevidde navn brukes hvor som helst du trenger for å referere til et område eller en liste som kan variere i størrelse. Nyt!